如果翻譯 Epoch的話會是時代,但我把它理解成的訓練一批次,也就是訓練集資料通過一次正向傳播和一次反向傳播。
DAY13的時候有介紹過的過度擬合以及欠擬合。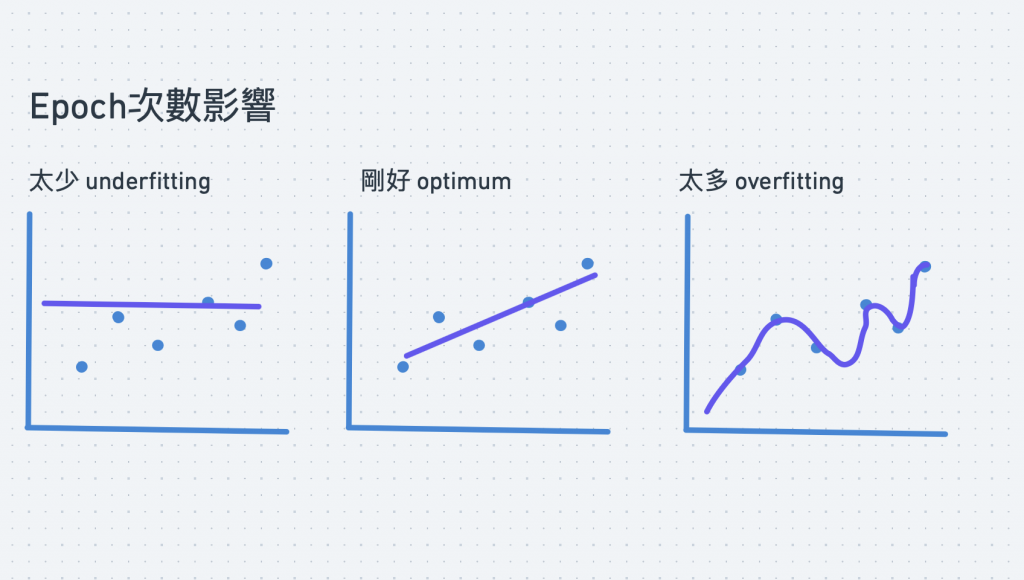
批次影響的是訓練一次的數據量,所以考慮數據較多的時候模型通常會比較準確,但相對會花費的時間也會比較多,在相同時間下就可以增加修正的次數。可以把其和批次想成是反比,當epoch多的話,一個批次中的資料就可以少一些。
但以上這兩格的數值都沒有絕對的對錯,只有比較適合或是能讓神經網路更精準的數值。
Data set size = Iteration * Batch size (1 Epoch)
Iteration = (Data set size / Batch size)* Epoch
迭代次數取決於這個資料及總共分成幾批,然後要訓練幾次,因此迭代可以理解為訓練一個batch。
也就是DAY11的提到的損失函數以及梯度下降,學習率越大收斂的會越快,所以可以在初期先將學習率調大,越接近時再慢慢縮小。


 iThome鐵人賽
iThome鐵人賽